Problem #130
Tags: aggregate analysis, depth first search
Consider the code shown below. It shows DFS as seen in lecture, with one modification: a print statement in the for-loop.
def dfs(graph, u, status=None):
"""Start a DFS at `u`."""
# initialize status if it was not passed
if status is None:
status = {node: 'undiscovered' for node in graph.nodes}
status[u] = 'pending'
for v in graph.neighbors(u):
print("Hello!")
if status[v] == 'undiscovered':
dfs(graph, v, status)
status[u] = 'visited'
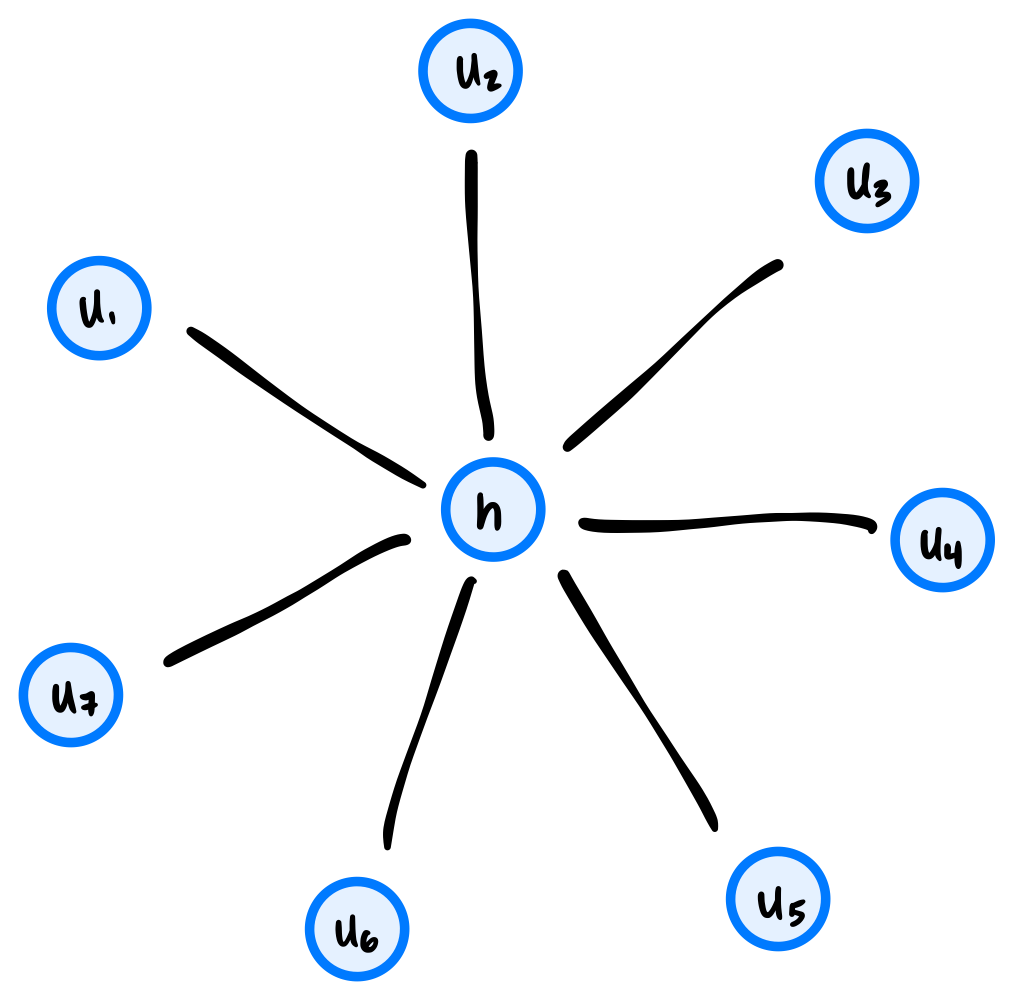
How many times will "Hello!" be printed if dfs is run on the graph below using node \(u\) as the source? Note that dfs will not be restarted if the first call does not explore the whole graph.
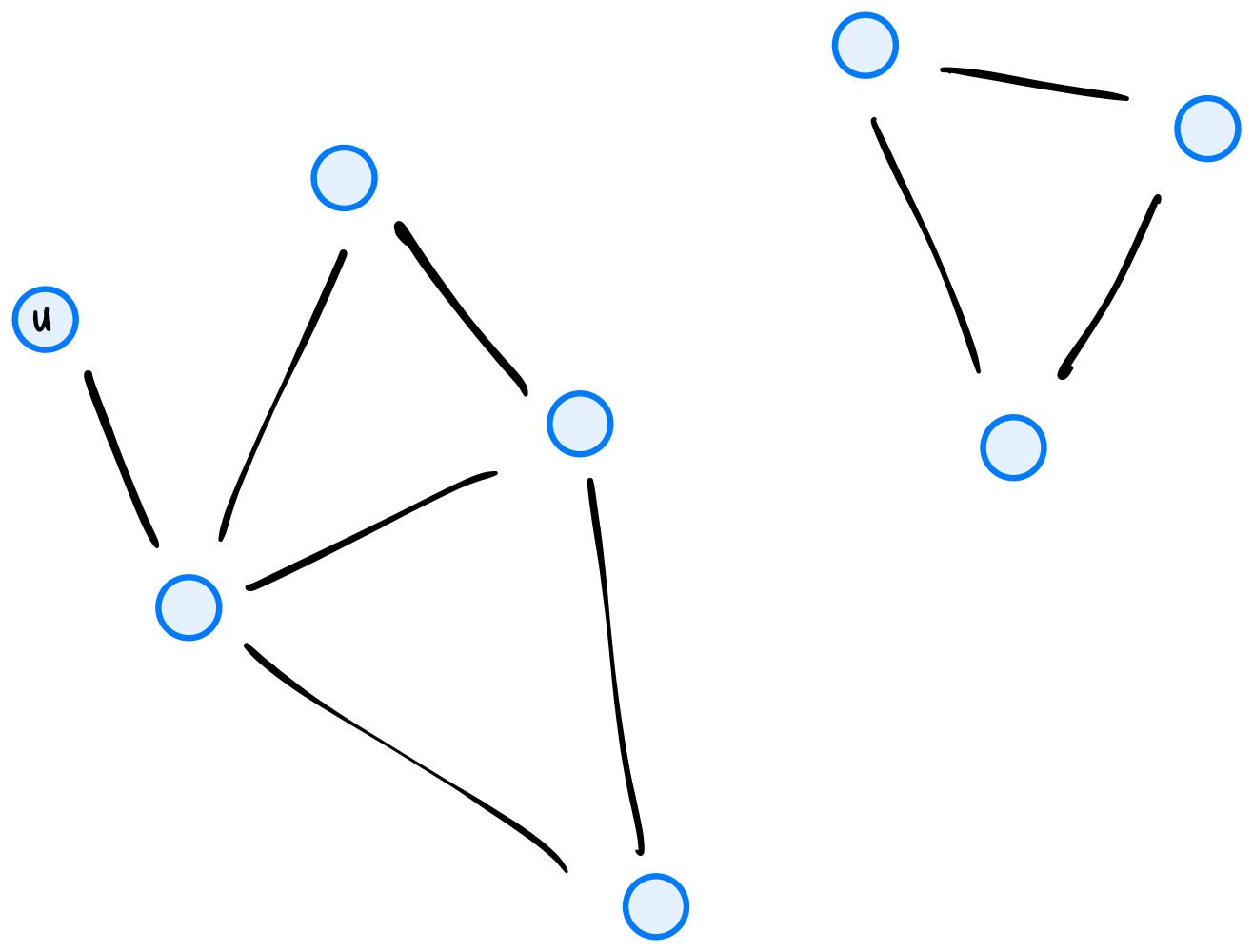
Solution
12